

Unlike human beings who often learn for the intrinsic value of knowing something, machine-learning is almost always purpose-driven. Your job as the machine's developer is to determine what that purpose is before you start development. With neural network regression and classification models, you then need to decide on the methodology that will best serve that purpose. Ask yourself, “Am I looking at a classification problem, a regression problem, or a clustering problem?” Those are the three things artificial neural networks do best: classification, regression, and clustering. Here’s how you choose:
1. Classification is best when you need to assign inputs to known (labeled) categories. There are two types of classification:
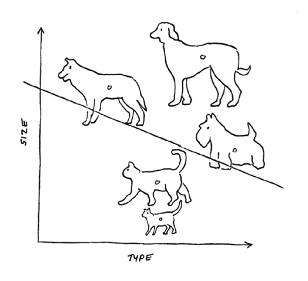
- Binary classification is used when you have only two categories; for example, a machine learning algorithm may create a line graph that distinguishes between dogs and cats based on their size and type, as shown below.
- Multi-class classification is used when you have three or more categories; for example, if you need a system with a classification model that can place customers in four categories. These are very dissatisfied, dissatisfied, satisfied, and delighted.
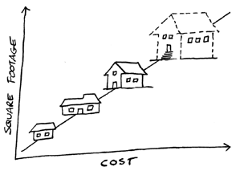
2. Regression is best when you need to predict a continuous response value in regression analysis. So you could create a system that could predict the value of a home based on certain criteria, such as square footage, location, number of bedrooms and bathrooms.
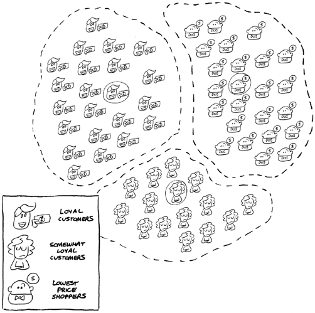
3. Clustering is the right choice when you want to identify patterns in the data and have no idea what those patterns may be; for example, if you want to identify patterns among loyal, somewhat loyal, and un-loyal customers.
Supervised Versus Unsupervised Learning

Classification and regression problems involve supervised learning. This uses training data, to teach the machine how to associate inputs with outputs.
For example, you may feed the machine a picture of a cat and tell it, "This is a cat." You feed it a picture of a dog and tell it, "This is a dog." Then, you feed the machine test data; for example, a picture of a cat without telling the machine what the animal in the picture is, and the machine should be able to tell you it's a cat. If the machine gives the incorrect answer it makes adjustments to improve its prediction accuracy.
Clustering problems are a form of unsupervised learning. You feed the machine data inputs without labels, and the machine identifies common patterns among the inputs without labeling those patterns.
Solving Classification and Regression Problems
Classification is one of the most common ways to use an artificial neural network for categorical data processing.
So credit card companies use classification to detect and prevent fraudulent transactions. The human trainer will feed the machine an example of a fraudulent transaction and tell the machine, "This is fraud." The trainer then feeds the machine an example of an honest transaction and tells the machine, "This is not fraud." As the trainer feeds more and more labeled data into the machine, it learns the patterns in the dataset that distinguish fraudulent transactions from honest transactions through regression analysis.
The machine may be set up with three output nodes (one for each class). If a transaction is highly characteristic of fraud, the Fraud neuron in the output layer fires to cancel the transaction and suspend the card. If a transaction is less characteristic of fraud, the Maybe Fraud neuron fires to notify the cardholder of suspicious activity. If the transaction is even less characteristic of fraud, the Not Fraud neuron in the output layer fires and the transaction is processed.
Solving Regression Problems
In regression problems, the machine tries to come up with an approximation based on the dataset input. During the training session, instead of showing the machine how inputs are connected to labels, you show the machine the connection between a known outcome and the variables that impact that outcome. Imagine the amount of time it takes to drive home from work varies depending on weather conditions, traffic conditions, and the time of day, as shown below.
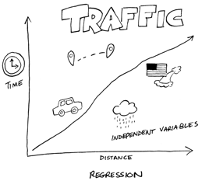
A stock price predictor would be another example of machine learning used to solve a regression problem, typically employing a regression model for prediction. The stock price would be the dependent variable and would be driven by a host of independent variables, including earnings, profits, future estimated earnings, a change of management, accounting errors or scandals, and so forth.
One way to look at the difference between classification and regression is that with classification the output requires a class label, whereas with regression the output is an approximation or likelihood.
Frequently Asked Questions
What are the basic principles behind artificial neural network classification models?
Neural networks can spot patterns. They do this by learning from data.
First, you train a neural network model using a dataset to evaluate its performance. This dataset, containing known answers, allows for the neural network to predict outcomes with higher accuracy. The network learns by adjusting its inside settings. It uses a method called stochastic gradient descent. This method helps it guess better by lowering the mistakes. These mistakes are measured by a metric called a loss function, like cross-entropy, in tasks where you need to sort things into categories.
Think of the process like teaching a someone to recognize animals. At first, the child makes mistakes, but with guidance, they learn to get it right.
1. Neural networks learn from data, adjusting their parameters each time.
2. They use a method that helps them improve their predictions by fixing mistakes.
3. This learning helps them sort and classify complex patterns correctly
The end goal of this is that the neural network becomes smarter and can make accurate classifications.
Can artificial neural networks be used for linear regression as well as classification in data science?
Yes, you can use neural networks for both predicting numbers and sorting items into groups. Here's how:
1. For predicting numbers, the network learns to predict continuous outcomes.
2. It adjusts its weights based on the difference between its predictions and the actual numbers.
3. It often uses mean square error, which measures these differences, to improve.

This is my weekly newsletter that I call The Deep End because I want to go deeper than results you’ll see from searches or LLMs. Each week I’ll go deep to explain a topic that’s relevant to people who work with technology. I’ll be posting about artificial intelligence, data science, and ethics.
This newsletter is 100% human written 💪 (* aside from a quick run through grammar and spell check).
More sources:
- https://www.semanticscholar.org/paper/4ea31e4721e513fc07d8fd1a4c475b3df5a4e2f9
- https://www.semanticscholar.org/paper/904cdcee1e5d695d328728502814b0ae107244c6
- https://pubmed.ncbi.nlm.nih.gov/19068426/
- https://www.semanticscholar.org/paper/942ec6ef13a51edd3e154cacf35db76594d24c23
- https://www.semanticscholar.org/paper/d406fff009c0483bdf938e17cbc6fdd9ced04efd
- https://www.semanticscholar.org/paper/412857cb6883599d19776a213531f6a532b317c6
- https://arxiv.org/abs/2005.08054
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8001442/
- https://www.semanticscholar.org/paper/4b23e5dc92a9708e4b360c99e84284b58914630a
- https://www.semanticscholar.org/paper/cd1985a9fa610854c5bd85d56d01fa8641853f1f
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9880304/
- https://www.semanticscholar.org/paper/a91b46c3c2cb0420fbf3cce5212c05097eb5a1fb
- https://www.semanticscholar.org/paper/4a4bc0bed660d063b430a5f177c99d35d76111f9
- https://arxiv.org/abs/1712.04555
- https://www.semanticscholar.org/paper/9104d81498241206b72f969f201a04418a6fe62a
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10638304/
- https://www.semanticscholar.org/paper/6ea5d4033575bc14af91b45a33b4240e6441264b
- https://www.semanticscholar.org/paper/7100211dac7d24a0fb1bbcdc85521619d2c38a14