

There are three types of problems that machine learning is generally used to solve:
- Classification
- Regression
- Clustering
Clustering has numerous applications in a wide variety of fields:
- In biology, Using clustering methods, the reconstruction of genetic patterns can provide insight into how different organisms are related in terms of evolution and pattern recognition.
- In medicine, clustering can analyze patterns of antibiotic resistance among different bacteria, to identify patterns in x-ray images that signal a higher risk of certain diseases and genetic patterns that may be at the root of certain hereditary illnesses.
- Businesses may apply clustering to market segmentation. This is when you want to aggregate prospective buyers into different groups using k-means clustering, so the business can more effectively target its marketing efforts, as shown below 👇.
- In social networks, clustering can be used to identify “similar” communities within the social network and to introduce members who have shared interests.
- Search engines use clustering to present relevant results.
- Law enforcement can use clustering to identify locations that have a greater frequency of certain types of crime and to analyze online communications for patterns that may be related to a potential terrorist attack.
- Educational institutions can use visualization techniques to enhance learning. may use clustering to identify conditions that place students at a greater risk of poor performance.
Recognizing the Limitations of Supervised Learning

Unlike classification and regression problems, which employ supervised learning, clustering problems rely on unsupervised learning. With this learning, you have clearly labeled data or categories that you are trying to match inputs to. For example, you may want to classify homes by price or classify transactions as fraudulent or honest.
Unfortunately, this type of learning is not always an option. If you do not have clearly labeled data you cannot use supervised learning. In other applications, you may not be interested in classifying your data into categories created by humans. Instead, you want to see how your neural network clusters the data to call your attention to patterns you may not be looking for.
In these cases, unsupervised learning is the better choice. With unsupervised learning, you let the neural network cluster your data into different groups.
Considering Business Clustering Problems
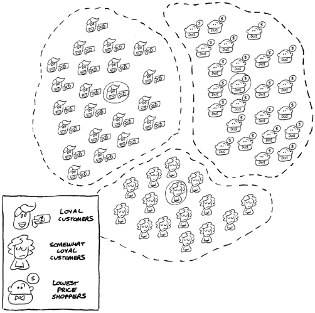
One of the more interesting applications of clustering is its use by large retailers who use k-means clustering to decide whom to invite to their loyalty programs or when to offer promotions. With unsupervised learning, the machine may identify three clusters of customers. These could be loyal, somewhat loyal, and not loyal. (The not loyal customers always buy from whichever retailer offers the lowest price.) Knowing these clusters, the large retailers create strategies to try and elevate somewhat loyal customers to loyal customers. Or they could invite their loyal customers to participate in special promotions.
Other companies use based clustering to decide where to place new stores. For example, a seller of athletic footwear may feed demographic and sales data into an artificial neural network to find locations that have the highest concentration of active runners or locations where customers allocate a higher percentage of their income to outdoor recreation.
Choosing the Right Approach
When you decide to use machine learning to solve a problem, what is most important is that you choose the right approach for the problem you are trying to solve. Classification is great when you know what you are looking for and can teach the machine the relationship between inputs and labels or between independent variables and a dependent variable, a process essential in supervised learning and pattern recognition. Clustering is a fundamental tool for gaining insight. You could identify clusters for seeing things in a different way, a way you may never have considered. After all, there is much more unlabeled (unstructured) data available than there is labeled (structured) data, making unsupervised clustering and data mining techniques critical for pattern recognition.
When you’re trying to decide which approach to take first ask yourself what problem you’re trying to solve or what question you need to answer. Then ask yourself whether the problem or question is something that can best be addressed with classification, regression, or clustering. Finally, ask yourself whether the data you have is labeled or unlabeled.
By answering these questions, you should have a clearer idea of which approach to take: classification or regression (with supervised learning) or clustering (with unsupervised learning).
Frequently Asked Questions
What is the primary use for clustering algorithms?
The main job of artificial neural network clustering algorithms is to group data points. Data points in the same group are more alike than those in other groups.
This is helpful for sorting data without labels, looking at data using plots, and finding patterns. Neural networks use their deep learning skills to do this grouping.
Which clustering algorithm is commonly associated with neural networks?
You have two tools for sorting data in neural networks: k-means clustering and vector quantization.
- Self-Organizing Map (SOM)
- Autoencoder
The Self-Organizing Map helps you pull out key features and see patterns in your data. It works well with high-dimensional data, which means data with lots of features.
An Autoencoder, on the other hand, helps you group data without needing labels. It does this by learning to compress and then rebuild the data. This process helps it find interesting patterns and structures in your data set.
How does the K-means algorithm integrate with neural network-based clustering?
You can use the K-means method with neural networks to make better groups of data.
First, K-means sorts the data into set groups. It also adjusts the data to fit better.
Then, neural networks take these groups and improve them. They do this by learning without help. They keep making the features better each time.
This way, the final groups are more accurate and easy to understand, enhancing the effectiveness of unsupervised clustering in data analysis.
What role does feature extraction play in neural network clustering?
You need to know that feature extraction is key for neural network clustering. It picks out the most important parts of the input data using parameters and network layers.
This makes the data smaller and easier to work with. It also makes the clustering process faster.
You can use layers called convolutional networks and other tools to do this, adjusting weights and parameters as needed. These tools help recognize patterns. They also make it easier to see and understand the data.
How do you visualize the results of a neural network-based clustering?
You can see the results of a neural network clustering by using Python tools. Use Matplotlib to make graphs. Use TensorFlow or Keras for deep learning, especially for complex pattern recognition and clustering tasks. These tools show how data points group together using clustering methods. You can easily check the clustering patterns. You can see if the neural network works well. You can also understand how the data relates to each other.
What programming languages or frameworks are preferred for implementing neural network clustering algorithms?
Python is the best programming language for creating neural network clustering programs. It is simple to use.
It has powerful tools like TensorFlow, Keras, and NumPy. These tools help with deep learning tasks. They have pre-made network parts and import functions for quick setup.
They help with automatic differentiation, which means they can adjust themselves. They help prepare and show data. They make it easy to develop, train, and use clustering models quickly.

This is my weekly newsletter that I call The Deep End because I want to go deeper than results you’ll see from searches or LLMs. Each week I’ll go deep to explain a topic that’s relevant to people who work with technology. I’ll be posting about artificial intelligence, data science, and ethics.
This newsletter is 100% human written 💪 (* aside from a quick run through grammar and spell check).More sources:
- https://www.nature.com/articles/s41598-023-32790-3
- https://www.xenonstack.com/blog/artificial-neural-network-applications
- https://hbr.org/2019/07/building-the-ai-powered-organization
- https://www.forbes.com/advisor/business/software/ai-in-business/
- https://www.investopedia.com/how-ai-is-used-in-business-8611256
- https://sproutsocial.com/insights/ai-in-business/
- https://www.pmi.org/explore/ai-in-project-management
- https://www.forbes.com/sites/rachelwells/2023/11/22/8-ai-tools-every-project-manager-needs-in-2024/
- https://blog.hubspot.com/marketing/ai-project-management
- https://www.techtarget.com/searchenterpriseai/feature/How-AI-is-transforming-project-management
- https://www.zenhub.com/ai-project-management-a-guide
- https://itrexgroup.com/blog/how-to-implement-ai-in-business/
- https://zesium.com/9-simple-steps-how-to-effectively-implement-ai-in-business/
- https://www.forbes.com/sites/billconerly/2024/03/22/ai-implementation-in-business-lessons-from-diverse-industries/